
With over 50 plugins on the Bubble.io marketplace currently related to Artificial Intelligence (AI) providers; it hardly seems necessary for there to be any more. Yet, when viewing these plugins, it starts to become apparent that a majority are all built around a single provider of AI models, OpenAI. There are a few more available that use other model providers, such as Mistral AI and WriteSonic AI. However, out of all these available many of them vary in their ease of customization and are limited in their functionality. There is a need for a plugin that provides improvements in these areas.
The AI Toolbox Plugin is a valuable addition to any website that wants to have a fully customizable AI. It allows for full customization of model settings, as well as offering a multitude of model providers, such as OpenAI, Anthropic AI, Google Vertex AI, Mistral AI, and many others. The AI Toolbox offers more than model customization and access to multiple providers. It integrates both Large Language Models (LLMs) and Chatbots into becoming more than just basic models, turning them into powerful chains and agents. Chains and agents allow the model to perform a series of tasks that use a series of prompts and powerful tools to guide the generation of their response. These are just a few of the currently available features of the AI Toolbox Plugin with even more planned for the future.
The AI Toolbox Plugin will be a useful product for any No-Code website on Bubble. With several features available at launch and many more planned for the future it will continue to be an ideal asset for creating custom AI Models. It is very user friendly and has many options for modification that include pre-built and fully custom features. Each option for customization is well documented and explains how to get the most out of each modification available.
Features The AI Toolbox Offers
The AI Toolbox offers multiple features that make developing a custom AI for no-code sites an easy and straightforward process. It is able to be fully customized and even offers predesigned defaults to make getting started a quick process. With advanced features such as chains and agents, it turns chatbots into a powerful asset that can complete tasks in a specified manner, while giving it access to special tools to increase its capabilities and reasoning.
Full Model Customization
Getting Started
Getting the AI model up and running is a matter of 3 quick steps. First, add the chatbot element to the page. Next, set the model provider and set the model API key in the element or on the plugins page. Then, add a workflow to generate a response. With that, a working chatbot is born. Now, there won’t be a way to see any response on the page, but with an input, a button, and text element on the page it will have all the basics elements needed to fully set it up to generate responses from the input element on the page.
In order to have more functionality there are additional settings that can be customized. Selecting from a variety of models that a provider has can be done by setting the model selection. Every provider has a variety of models that are more powerful or offer additional functionality than the default model. Clicking show documentation under each model’s dropdown will outline basic differences between each option.
Model Settings
Below the model selections is the model settings section where a variety of settings can be set in order to modify the AI’s response generation. These settings are what give the ability to fully customize responses and generate more random or predetermined responses.
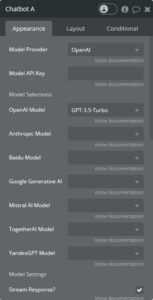
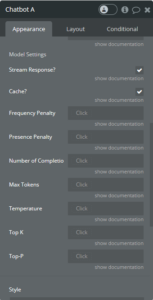


The AI Toolbox Chatbot Settings in the Bubble.io Editor
Stream Response
Stream response allows the model to send the response as it is being generated. Clicking the checkbox will set it to true, and if it is set to false then the response will be sent in whole once it is fully generated.
Cache Response
Setting cache response to true allows the model to be cached in the browser and will save responses for a particular input, allowing it to reuse responses when given the same input, reducing costs and saving API calls.
Frequency Penalty
Avoiding repetition and creating more varied responses is done by modifying the frequency penalty. It has a range of 0.0 to 2.0 and by default is set to 0.0.
Presence Penalty
The presence penalty reduces the presence of negative content and prevents it from having a strong bias. It has a range of 0.0 to 2.0 and by default is set to 0.0.
Number of Completions
Changing the number of completions allows multiple responses from the same input. However, this only works for a few models currently, OpenAI and Together AI. It can return a maximum of 10 and is set to 1 by default.
Max Tokens
Setting the max tokens value alters the length of the response generated, cutting off the response when it reaches the number of tokens for its response. The max value varies depending on the model selected, by default it is set to -1 which will allow it to use the maximum number of tokens needed to respond. Keeping it at this value is best unless a lower processing time and cost is desired for responses. A token can be thought of as a word in most cases, but sometimes when generating a word, it may split the word into multiple tokens, some examples of this would be “gene rate”, “insid io us”, or “tim e”.
Temperature
The temperature controls the level of randomness, with a higher value causing more randomness in the model’s response, and a lower value creating a more predictable response. It has a range from 0.0 to 2.0 and is set to 0.8 by default.
Top-K
The top-K works directly with the temperature when generating responses. As it selects the next token in a response it chooses from the next most probable tokens which are available based on the value set. If a value of 1 is set, then it will choose the next best model and will almost always result in the same outcome. When this is the case, it is known as greedy decoding. Setting the top-K to a higher value controls the variety of tokens generated, and when used with a low temperature, this allows for a controlled response with more variance in vocabulary. It should also be noted that some models do not make use of the top-K and it will have no effect on the generation, so in those cases it is recommended to use top-P to achieve similar results.
Top-P
Top-P or Nucleus Sampling works similarly to top-K as it selects next few tokens and combines their probability values of being a good response to add up to the top-P value. A higher value allows for the selection of a larger set of words. When used with a high temperature it manufactures better control of the responses, allowing for more diverse outputs while maintaining some control over the generation of tokens. If used in combination with top-K it allows for a more restricted generation of tokens and can create a more deterministic response.
All of these model settings work together in some way to add more variety or restriction to the responses that a model generates. In most cases a higher value will result in more variance and a lower value will result in more control. Use the settings to determine how much variety is needed for the model in how it should respond. However, this is still just the simplest of customizations that can be done to the model. The addition of prompts, chains, and agents will allow for even more control over the responses and behavior of the model, empowering the creation of the most useful AI possible for any task needed.
Chat History
The initial model when generated will work primarily from the input given to generate a response. In order to have a conversation with the AI then it is necessary to provide it with a history of the conversation. Currently the chatbot will load in the provided history before it generates a response and will use the context of that conversation to recall what has already been said and will help with understanding the latest input. In order to load in the data, it must be formatted as a JSON-object with the following notation:
[{“MessageType: “Human/AI”, “Message”: “Previous human input/previous AI output”, “Model”: “AIModelProviderUsed”}]
An Example of how this might look when filled with data:
[
{
"MessageType": "Human",
"Message": "What are some good alternatives for a Peanut Butter & Jelly Sandwich? Either replacing the Peanut Butter or the Jelly with a different product.",
"Model": "OpenAI"
},
{
"MessageType": "AI",
"Message": "There are plenty of delicious alternatives to a classic Peanut Butter & Jelly sandwich! If you want to replace the peanut butter, you could try almond butter, cashew butter, sunflower seed butter, or even cookie butter for a different flavor profile. If you're looking to switch up the jelly, you could experiment with different fruit spreads like strawberry, raspberry, apricot, or even fig jam. Some other tasty combinations to consider are cream cheese and jam, honey and banana, or Nutella and strawberry. The possibilities are endless, and it all depends on your personal preference and taste.",
"Model": "OpenAI"
}
]The information is converted from this JSON-object into a buffer window memory for the AI. This buffer window memory works by formatting the messages into human and AI messages in order to give context of the most recent conversation. It lists the interactions of the conversation over time and accesses the most recent interactions in order to keep the buffer and loading of information from getting too large.
As long as the history is formatted correctly it will load it into the conversation. This allows for the data to be stored in the Bubble database and formatted for the plugin. To see how this can be achieved then view the demo page for the AI Toolbox Plugin. The data can also be stored in an external database and retrieved via an API call. Just be sure to format it as shown above or it will not work. It is important to note that the chat history must be updated each and provided to the AI again before asking another question in order to have a continuous conversation. The way chat history is currently structured does not allow for it to store a continuous log of inputs and responses. This is a function that may be implemented in the future; however, it will not allow for information to be saved if the page would be reloaded and therefore the chat history would only persist during the current page session.
In future updates, there will be additional history functionality added with Vector Stores, which allow for the data to be loaded into an easily searchable database for the AI to use that will make it simple to reference and pull data from that is useful for a response. This has many extra uses besides chat history, it can be used to load entire documents or databases for use as references within a response. Once this is implemented in the future it will likely remove the need for the current way of loading history since it will be better suited for use with chains and agents.
Custom and Prebuilt Prompts
Prompts are the backbone for shaping the overall behavior of the AI’s response. They are the set of instructions used to guide the model, help it understand context, and generate relevant output. Multi prompt chains provide access to multiple prompts and select the best to generate a response for a given input. Prompts are also used in agents to guide its thinking and choosing of the best tools. The AI Toolbox comes with some prebuilt prompts that can be used for a variety of purposes from physics and history questions to physical therapy to generating YouTube video ideas. It also allows for the creation of custom prompts so the behavior can be better modified and suited to any use case.
Multi Prompt Chains
Multi prompt chains are handy when creating a chatbot that is meant to be open ended and have a multitude of functionalities. How it works is that it routes input between multiple prompts. It makes this decision based on the context of the chat history and input, and using the basic chatbot from the initial model it chooses from a list of available prompts that would best suit the response. This is known as the router chain. The router chain then calls the appropriate destination chain that is built upon the basic model to have the corresponding prompt to guide its reasoning and response. If no prompt that is given is suitable for a response, a default will be used instead which is built to use a conversation chain that is built upon the basic model to have a guiding prompt of a friendly and talkative AI. This allows functionality even in cases where it is unsure of a response or how to proceed if the question asked does not conform to the available prompts. After it has selected the destination chain to use it will then generate the response for the input.
There are several prebuilt prompts created that offer a variety of use cases. They are somewhat basic in their current functionality and will likely be updated with more options in the future. In the meantime, it is possible to create custom prompts that can be used. Multiple custom prompts are allowed to be entered as a list of texts. Some ways this can be achieved by using Arbitrary Text filled with the text and split by a (), using an option set, or doing a search for some prompts saved in the Bubble database. A custom prompt must be well titled, have a short description of what it does, and detailed instructions for how it should behave. An example of how this might look can be seen in the following code snippet.
Prompt Title: “Friendly Helper”,
Prompt Description: “A friendly robot capable of answering questions and having a meaningful conversation”,
Prompt Template: “The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{chat_history}
Human:
{input}”The main bulk of the template is the guiding text at the start, but do not forget to include input variables for {chat_history} and {input} in order to include the necessary information for the AI to generate a response. Without these input variables the destination chain will not be created properly and will return an error when trying to generate a response. However, if they are forgotten or typed incorrectly, they will be added by the plugin. While multi prompt chains add a lot of functionality, they are still limited in what they are able to do. In cases where a single prompt is wanted, agents provide the perfect use and add additional functionality with tools.
Agent and Tools
The core idea of agents is to use the chatbot to choose a sequence of actions to take. What makes this different from chains, is that in chains this sequence of actions is hardcoded (in code). Meanwhile in agents, the chatbot is used as a reasoning engine to determine which actions to take and in which order. This means that each decision is made through a call to the model and results in multiple API calls before generating a final response. An agent is still similar to a multi prompt chain in that it uses a prompt to guide its reasoning when deciding what actions to take, however it only has access to a single prompt. While it lacks functionality in its diversity to tackle different scenarios, it does have the use of powerful Tools to extend its versatility. These tools allow the AI to connect with outside APIs in order to give it resources that it would not traditionally have.
For example, it can be used with Search API in order to connect the agent to the internet through various search providers such as Google and Amazon. This tool comes in handy when answering questions about current events. The Search API tool must be connected via an API key that is found on the account page after creating a profile on the Search API Website.
Another example would be using the web browser tool to give an agent the ability to visit a website and extract information. It exposes two modes of operation: when called by the agent with only a URL it produces a summary of the website contents and when called by the agent with a URL and a description of what to find it will instead use a text embedding model and an in-memory vector store to find the most relevant snippets and summarize those. A text embedding model works by capturing semantic relationships between words, allowing for a more meaningful representation of textual data. While there is currently not much support for text embedding models at this time, they do not have to be the same provider as the model for responses.
These tools are what give power to agents and allow them to interact with the world. For now, there are only a few different internet searching tools and a calculator available as tools, looking to the future there will be many more added by the next update. Agents will continue to grow as a powerful apparatus in the AI Toolbox as more functionality through tools is added to it.
How to Use the AI Toolbox
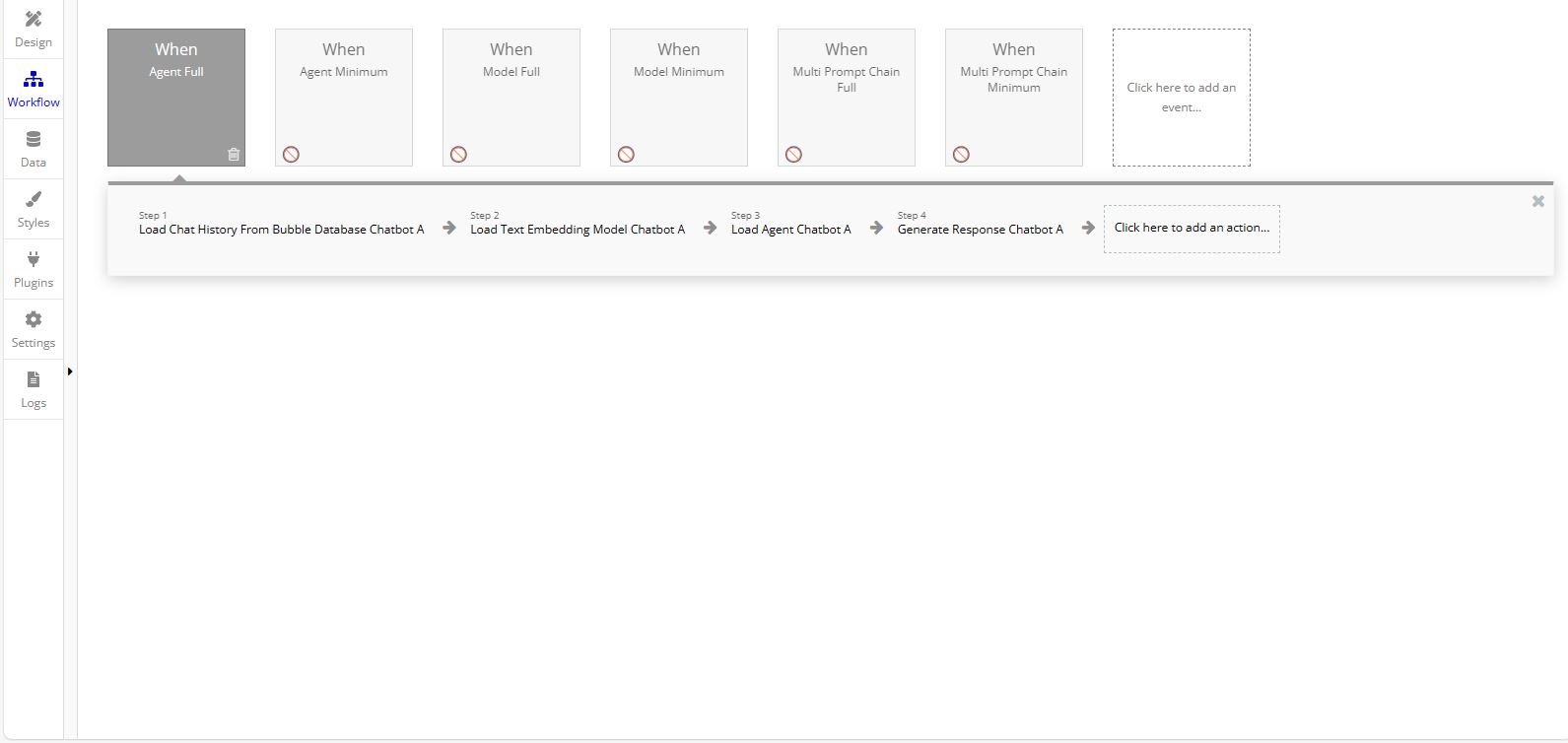
As outlined in the previous section, the AI Toolbox offers a variety of features that culminate into 3 methods for utilizing its potential. There is the basic model workflow, the multi prompt chain workflow, and the agent workflow. All of these allow for further customization, however in order for the model to generate a response properly then there are certain steps that must be followed.
There are two steps that are a part of each workflow. The first step is optional, Load Chat History from the Bubble Database. This step will take chat history that is provided in a JSON-object in the format, [{“MessageType: “Human/AI”, “Message”: “Previous human input/previous AI output”, “Model”: “AIModelProviderUsed”}], and converts it to a buffer window memory that can be used by the Model in order to access the most recent chat messages. The second step is the Generate Response step which will generate a response from the model, chain, or agent when given an input as part of an exposed state in the chatbot. This exposed state allows for the response to be accessed from the element within the Bubble editor.
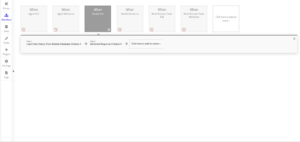


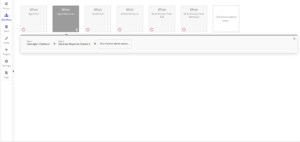
Example Workflows of How to Generate a Response Using Just a Model.
When only a model is used then the workflow looks like the following: Load Chat History from Bubble Database (Optional) > Generate Response. The basic model only uses the two steps that are in every workflow. It works this way because the model is created when the chatbot is loaded or updated on the page. This allows it to be run with just a simple workflow. However, multi prompt chains and agents will require a few more steps.
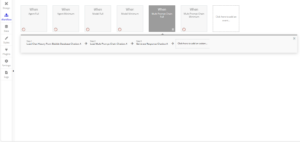


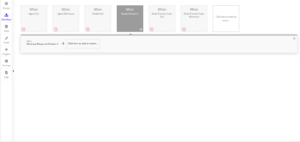
Example Workflows of How to Load a Multi Prompt Chain and Generate a Response.
The multi prompt chain is only one more step than the model on its own. A general workflow has the following steps: Load Chat History from Bubble Database (Optional) > Load Multi Prompt Chain > Generate Response. The Load Multi Prompt Chain step takes the input of prompts to be used as well as allowing for the creation of custom prompts. This allows for multiple custom prompts that are a list of texts. It requires a prompt name, prompt description, and prompt template. Some ways to create a list is to use Arbitrary Text and split the entries into a list, Get an Option from an option set of stored prompts, or Do a Search for prompts saved in the Bubble database. This then loads the chain to be used for when the Generate Response step starts. With this single addition before the Generate Response step, the workflow will create and generate a response using a multi prompt chain instead of a model.

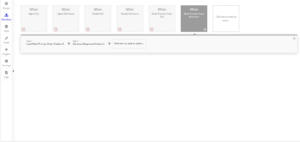
Example Workflows of How to Load an Agent and Generate a Response
The agent workflow has a few additional steps compared to the basic model. The order of the first two steps does not matter, they just must be before the Load Agent step. A general workflow would look like the following: Load Chat History from Bubble Database (Optional) > Load Text Embedding Model (Optional) > Load Agent > Generate Response. The Load Text Embedding Model step is only required when the web browser tool is used in the agent. It allows the web browser tool to gather information from a website and store it in a temporary database for the agent to reference information from. Once vector stores are added in a future update it will have additional uses, but for now this is the only use it has. The Load Agent step is where the Tools will be selected that the agent will use and load it to be able to generate a response. Since the agent is loaded before the Generate Response step, it will use the agent to generate the response.
It should be noted that in the case where an agent and multi prompt chain are both loaded for the same chatbot, the agent will take priority and will be used to generate a response and the multi prompt chain will be ignored. The reason for this is to avoid the overwriting of responses between the different functions. In the case where no agent, chatbot, or model is loaded to generate a response, the response will return a string reading “Model loaded improperly and did not generate a response. Check your settings.” While this case should almost never occur since it is required that information for a model to be created is specified, it is still possible if that information is left blank and will cause an error and result in this output.
Future Updates Planned for the AI Toolbox
More Models
The next update planned is to incorporate LLMs into the AI Toolbox. While it has not been mentioned much so far there is a bit of a difference between LLMs and chatbots. The most obvious difference is that chatbots are built to have long running conversations that utilize relevant information from the conversation so far in order to answer questions, and LLMs are trained to answer questions solely based on the input. This correlates to a less obvious difference in that chatbots are utilizing a list of all the chat messages as part of their input, and LLMs are utilizing a string prompt as their input. The reason LLMs were not implemented upon release is that chatbots in most cases can be used to fulfill the same use cases as LLMs because they are often backed by LLMs and fine-tuned for conversations.
The next step is to implement the LLMs available for the model providers already used for chatbots, as well as adding new LLMs, such as AI21, Aleph Alpha, Hugging Face, Replicate, WatsonX by IBM, and Writer. It is also planned to add a few more Chatbots, such as Cohere and Alibaba’s Tongyi Qianwen (Qwen). With this, even more diversity will be possible with AI Toolbox.
Additional Chains
Document Retrieval Chain
In a future update, it is planned to add some more functionality with chains besides just the multi prompt chain. The first is a two-chain process in order to create a document retrieval chain, which will utilize a separate chain that formats documents. They work together where the first document formatter chain takes a list of documents and formats them into a prompt, meanwhile the document retrieval chain takes the user input and passes that to a retriever that fetches the documents from the prompt, and this is all passed to an LLM to then generate a response.
Structured Output Runnable
The other future chain planned is a structured output runnable. This will be used in order to force the LLM to respond in more ways than just a pure text output. This will allow the output to be structured in a JSON format that will always return a response in the format that is given. For example, this can be used to parse an input from a user into the meaningful components in order to then be used as it is passed to another chain in order to generate a response based on the output from the structured output runnable.
Customization for Output Parsers
Currently each chain, agent, and model are structured to return the same style of output, where it returns the output as a string in the structure determined by the model. This is all done using an output parser defined by the AI Toolbox Plugin. A custom structured output parser allows the model to return an output in any way specified JSON object. A use case for this would be to return the response from the model as well as the source for the information. For example, the model could be programmed by saying “Format your output as a JSON object that adheres to the following schema: {“answer”: “answer to the user’s question”, “sources”: “sources used to answer the question, should be websites.” If you wanted that structure to be a listed response, then a list output parser would be useful for responses that return a list of answers as it can be used to return a comma separated list of strings.
If the model would be serving as an external host that is then sending a response to another website, then it would be useful to have an HTTP response output parser, which will allow for responses created by the model to be sent as an HTTP response to an API that is fetching an answer from a model. This method will allow for streaming of responses as chunks as well as returning entire responses.
If a model is generating an XML as a response, then it will be possible to use the XML Output Parser to turn the response into JSON format for easier use. All of these output parsers are planned for future updates and are expected to be used with ease and extend the functionality of the AI Toolbox.
Extra Agent Tools
Several agent tools are planned for an update soon to allow extra functionality and integration with external APIs. Some planned tools will be able to interact with Gmail, Google Calendar, Google Places, Discord, Wikipedia, Wolfram Alpha, and also be able to interpret and create usable Python code. While these will all add extra functionality in their own ways, they each extend the possibilities that agents can perform. However, there is even more they can achieve when given access to vector stores and the ability to reference previous chat messages and documents saved.
Vector Stores
Vector stores are a way to store and search through unstructured data. It does this by embedding the data and storing the resulting embedding vectors. Then once a query is input it embeds that and uses it to retrieve embedding vectors that are the “most similar” to the embedded query. It is great at both storing embedded data and searching for data.
There are several different vector stores that are available, and it is currently planned to implement Chroma, Pinecone, Supabase, Vercel Postgres, and Redis as available vector stores that can be utilized in the AI Toolbox. These will come in handy for both saving chat history but will also be useful in adding documents and other data that a model can use when responding to a query. Vector stores are also the final piece that will be needed for the AI Toolbox to jump to the next big step in future updates.
Retrieval Augmented Generation (RAG)
All of these planned integrations build into the next big step for the AI Toolbox, known as RAG or retrieval augmented generation. RAG is a technique for augmenting LLM knowledge with additional data. RAG allows for applications to answer questions about specific source information, becoming a sophisticated Q&A chatbot. What makes RAG a huge improvement over tradition LLMs is that while they are able to reason about a wide range of topics, their knowledge is limited to the data they were trained on, and when it is desired to use private data or new public data, then it is necessary to augment the knowledge of the model with that new information. To simplify the way this is done is that the model loads the data, breaks it into small chunks, and stores the information for the model to access later, retrieving the information needed based on the input and generating an answer. It is this process of loading the appropriate information and inserting it into the model that is known as retrieval augmented generation.
Frequently Asked Questions (FAQ)
What is an AI Model?
An AI model is a trained algorithm designed to perform tasks or make decisions based on input data. They are designed to mimic human intelligence, learning from data, identifying patterns in text, and making predictions or decisions on their own. The AI Toolbox divides AI models into two categories, Large Language Models and chatbots.
What is a Large Language Model (LLM)?
LLMs are a class of AI models designed to understand and generate human-like text based on vast amounts of training data. They specialize in taking a single text input and generating a text response. They are utilized for a variety of applications such as language translation, content generation, and sentiment analysis.
What is a Chatbot?
Chatbots are a class of AI models designed to simulate conversation with humans. They specialize in understanding natural language inputs and responding in a conversational manner. They serve a wide range of purposes from customer service, information retrieval, virtual assistants, and entertainment.
What are Chains?
Chains are a sequence of calls that the model performs in order to generate a response. The sequence will always follow the same order every time and helps to guarantee that a model will perform as programmed. Chains are able to work together with other chains in order to get to a final response. A complex chain that is currently implemented is the multi prompt chain.
What is a Multi Prompt Chain?
The multi prompt chain works by routing between multiple selected prompts based on the input provided. This is useful for when a model should have multiple functionalities but needs to select the best prompt to guide a response. The multi prompt chain utilizes 3 additional chains called; router chains, destination chains, and conversation chains in order to generate a response.
What is a Router Chain?
A router chain is designed to route between potential options it is given. The router chain for a multi prompt chain is given a router prompt to guide its decisions based on the chat history, human input, and available prompts. It makes these decisions based on 20% of the most recent input, and 80% on the previous chat history, in order to decide which of the prompts it should route to as part of a destination chain. If none of the prompts are determined to be a good fit for generating a response, then it will use a default chain based on a conversation chain.
What is a Destination Chain?
Destination chains are built to guide a response based on a given prompt. They have access to the given chat history to provide the model with more context and will generate a response based on the human input.
What is a Conversation Chain?
A conversation chain is designed to work as a friendly AI companion that is able to carry a conversation with a user based on their input and previous chat history. Within the context of a multi prompt chain it is the designated default for cases where the destination chains are determined by the model to not be useful for generating a response based on the input.
What is an Agent?
An agent is a special model that is able to choose a sequence of actions to take in order to generate a response. It uses reasoning in order to determine what actions it should take and what order to take them in. They are guided by a prompt to make informed decisions as well as chat history and the human input to reason for which tools it should use to generate a response.
What are Tools?
Tools are interfaces that an agent can use to give it extra functionality and interact with the world. The ones currently available for the AI Toolbox are those that give functionality to browse websites and Google for information as well as a calculator.
What is the Serp API Tool?
The Serp API Tool connects the Agent to Google’s search engine allowing it to scrape the search results for content. It must be connected with a Serp API key that can be found on the profile page after making an account at Serp API’s Website.
What is the Search API Tool?
The Search API Tool connects the agent to many different search engines such as Amazon, Google, and YouTube in order to gain more recent information related to a topic. This is connected through a Search API account after being created on the Search API Website.
What is the Web Browser Tool?
The web browser tool gives the agent the ability to visit websites and extract information and store that information in memory using a text embedding model. It can be given the URL of a website along with target information to look for in order to filter specific results.
What is the Calculator Tool?
The calculator tool gives the agent the ability to perform arithmetic operations. This is useful when wanting to give the model complex equations or theoretical calculations to perform.
What is a Text Embedding Model?
A text embedding model is a natural language processing model used to capture semantic relationships between words, allowing for a more meaningful representation of textual data. It ranks the data by a decided value and when looking for a reference it will compare the similarity of what is stored to what is being queried and use the most related data in order to help in generating a response.
What are Prompts?
Prompts are the set of instructions for a model that guides the model’s response. They help in understanding context and generating relevant and coherent outputs. Prompts are powerful in how they shape the thinking of the model. A poorly constructed prompt will have a detrimental effect on the outcome, so when creating a custom prompt, it is best to be as detailed as possible for instructing the models behavior.
What are Vector Stores?
Vector stores are databases that are embedded in the model’s memory that it is able to access when generating responses. They work by creating an index for each chunk of data that is saved and looking up the most similar index when retrieving information related to an input. Vector stores perform all the work of storing embedded data as well as performing the search of the data.
What are Output Parsers?
Output parsers modify the output of the response generated by a model. The instructions given by an output parser can change the format of the response from a normal string and create a more structured data type. They work similarly to a prompt, but only interact with the final output and how it is formatted, with no impact on the thinking of the response.
What is Retrieval Augmented Generation (RAG)?
RAG is an advanced technique for adding additional knowledge to a model. It allows for indexing of custom and private data into the memory of the model and allows for retrieval of the relevant information to pass to the model when generating a response. This works by loading the data from a document, splitting it into chunks, using a text embedding model to parse the data from documents, and saving the data into vector stores in order to index the information. When a question is asked to the model, it then retrieves the relevant split up data from the vector store and feeds it into a prompt with the question and uses that prompt in order to generate an answer.
Areas of Note
API Keys Are Public
The AI Toolbox works on the frontend of Bubble and is making API requests to various model providers this way. All of this is done on the frontend in order to be fast with sending requests and receiving responses. This however comes with a downside in that the requests are made using CORS or Cross-Origin Resource Sharing, which is a sharing of resources from a browser to a server. When sending a request this way it makes the API keys public and thus, they are able to be viewed by users on the site by viewing the network tab in the developer tools for a browser. So, it is best to make sure that no private keys are being used and only public ones are provided to the models.
Multi Prompt Chains Have a Default
Multi prompt chains allow for use of premade prompts as well as customs prompts. However, in cases where no prompts are provided or the provided prompts are not useful in generating a response, a default prompt will be used. This default prompt is called a default chain and is described as a “Friendly AI that is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.” While this may not be ideal for all use cases it should only engage if provided prompts are not useful for answering an input.
It is recommended to create prompts that will always work and should not allow the default to work. It is possible to create an override for the default by creating a custom prompt called “default” and having the description be, “The default prompt when no other prompt is useful”, and inserting a custom prompt template that should be the default.
Chat History Must Be Manually Updated
The model is initially loaded with no chat history and is treated like a brand-new model every time. When an action is run to Load the Chat History from a Bubble Database it will load any messages provided as part of the prompt, or input for the model to give it more context of the conversation. Once it generates a response, the newest input and response are not saved into the data, and if another input was sent after then the most recent conversation would not be included. In order to have it included in the next response, another action must be run to load the chat history before loading the model and generating another response.
Incorrect Outputs Are Possible from Together AI
Together AI is a newer model provider that has a lot of available Models from several sources. However, it is known to cause a few issues at this time that other models do not. The thinking that the Together AI models use will cause them to generate responses differently from the models of other providers. On some occasions it will return a structured output in the form of a JSON object instead of a text response. This will still provide useful information as a response to answer the user, however it will not always look like a normal response. On rare occasions it may even return an error with its thinking that causes it to be unable to create a final response and no response will be returned at all. Overall, it works normally around 90% of the time, and will be fully operational in future updates.
Conclusion
The AI Toolbox is the best plugin available for any website seeking to have a fully customizable AI for their website. With an ever-increasing number of model providers as well as the LLMs and chatbots that they provide, it will continue to grow as a powerful asset for any no-code web designer. It provides customizations that will increase the abilities of the model by using prompts, chains, and agents to guide models in their response generation.
The user-friendly interface makes customization a breeze and understanding the interactions of each feature is easy with the documentation under all the settings. This helps all designers to save time and create the AI they need without having to dedicate a lot of money and time to developing and understanding the inner workings. It is easy to get up and running and only a few steps are needed to make the model work.
With more features planned for the future the AI Toolbox Plugin is only going to continue improving and becoming the most versatile AI plugin available for Bubble. Click here to add the AI Toolbox Plugin and start creating a custom AI today.
